
底层架构
先停一下,学习之前,先看下如何学习,两篇不错的干货文章分享给你,一定要点开看下
6.1 存储架构
6.1.1 分段存储
开篇讲过,kafka每个主题可以有多个分区,每个分区在它所在的broker上创建一个文件夹
每个分区又分为多个段,每个段两个文件,log文件里顺序存消息,index文件里存消息的索引
段的命名直接以当前段的第一条消息的offset为名
注意是偏移量,不是序号! 第几条消息 = 偏移量 + 1。类似数组长度和下标。
所以offset从0开始(可以开新队列新groupid消费第一条消息打印offset得到验证)

例如:
0.log -> 有8条,offset为 0-7
8.log -> 有两条,offset为 8-9
10.log -> 有xx条,offset从10-xx

6.1.2 日志索引
每个log文件配备一个索引文件 *.index
文件格式为: (offset , 内存偏移地址)

综合上述,来看一个消息的查找:
- consumer发起请求要求从offset=6的消息开始消费
- kafka直接根据文件名大小,发现6号消息在00000.log这个文件里
- 那文件找到了,它在文件的哪个位置呢?
- 根据index文件,发现 6,9807,说明消息藏在这里!
- 从log文件的 9807 位置开始读取。
- 那读多长呢?简单,读到下一条消息的偏移量停止就可以了
6.1.3 日志删除
Kafka作为消息中间件,数据需要按照一定的规则删除,否则数据量太大会把集群存储空间占满。
删除数据方式:
- 按照时间,超过一段时间后删除过期消息
- 按照消息大小,消息数量超过一定大小后删除最旧的数据
Kafka删除数据的最小单位:segment,也就是直接干掉文件!一删就是一个log和index文件
6.1.4 存储验证
1)数据准备
将broker 2和3 停掉,只保留1
docker pause kafka-2 kafka-3
2)删掉test主题,通过km新建一个test主题,加2个分区
新建时,注意下面的选项:
segment.bytes = 1000 ,即:每个log文件到达1000byte时,开始创建新文件
删除策略:
retention.bytes = 2000,即:超出2000byte的旧日志被删除
retention.ms = 60000,即:超出1分钟后的旧日志被删除
以上任意一条满足,就会删除。
3)进入kafka-1这台容器
docker exec -it kafka-1 sh
#查看容器中的文件信息
/ # ls /
bin dev etc home kafka lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
/ # cd /kafka/
/kafka # ls
kafka-logs-d0b9c75080d6
/kafka # cd kafka-logs-d0b9c75080d6/
/kafka/kafka-logs-d0b9c75080d6 # ls -l | grep test
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-0
drwxr-xr-x 2 root root 4096 Jan 15 14:35 test-1
#2个分区的日志文件清单,注意当前还没有任何消息写进来
#timeindex:日志的时间信息
#leader-epoch,下面会讲到
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 4
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 0 Jan 15 14:35 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
4)往里灌数据。启动项目通过swagger发送消息
注意!边发送边查看上一步的文件列表信息!

#先发送2条,消息开始进来,log文件变大!消息在两个分区之间逐个增加。
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 875 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#继续逐条发送,返回再来看文件,大小为1000,到达边界!
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#继续发送消息!1号分区的log文件开始分裂
#说明第8条消息已经进入了第二个log
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 14:35 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 10485756 Jan 15 14:35 00000000000000000000.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 125 Jan 15 14:46 00000000000000000008.log #第二个log文件!
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持续发送,另一个分区也开始分离
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 20
-rw-r--r-- 1 root root 0 Jan 15 15:55 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 15:55 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 15:55 00000000000000000008.index
-rw-r--r-- 1 root root 625 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 15:55 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 15:55 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
test-1:
total 20
-rw-r--r-- 1 root root 0 Jan 15 14:46 00000000000000000000.index
-rw-r--r-- 1 root root 1000 Jan 15 14:46 00000000000000000000.log
-rw-r--r-- 1 root root 12 Jan 15 14:46 00000000000000000000.timeindex
-rw-r--r-- 1 root root 10485760 Jan 15 14:46 00000000000000000008.index
-rw-r--r-- 1 root root 750 Jan 15 15:55 00000000000000000008.log
-rw-r--r-- 1 root root 10 Jan 15 14:46 00000000000000000008.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 14:46 00000000000000000008.timeindex
-rw-r--r-- 1 root root 8 Jan 15 14:35 leader-epoch-checkpoint
#持续发送消息,分区越来越多。
#过一段时间后再来查看,清理任务将会执行,超出的日志被删除!(默认调度间隔5min)
#log.retention.check.interval.ms 参数指定
/kafka/kafka-logs-d0b9c75080d6 # ls -lR test-*
test-0:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
test-1:
total 8
-rw-r--r-- 1 root root 10485760 Jan 15 19:12 00000000000000000119.index
-rw-r--r-- 1 root root 0 Jan 15 19:12 00000000000000000119.log
-rw-r--r-- 1 root root 10 Jan 15 19:12 00000000000000000119.snapshot
-rw-r--r-- 1 root root 10485756 Jan 15 19:12 00000000000000000119.timeindex
-rw-r--r-- 1 root root 10 Jan 15 19:12 leader-epoch-checkpoint
6.2 零拷贝
Kafka 在执行消息的写入和读取这么快,其中的一个原因是零拷贝(Zero-copy)技术
6.2.1 传统文件读写
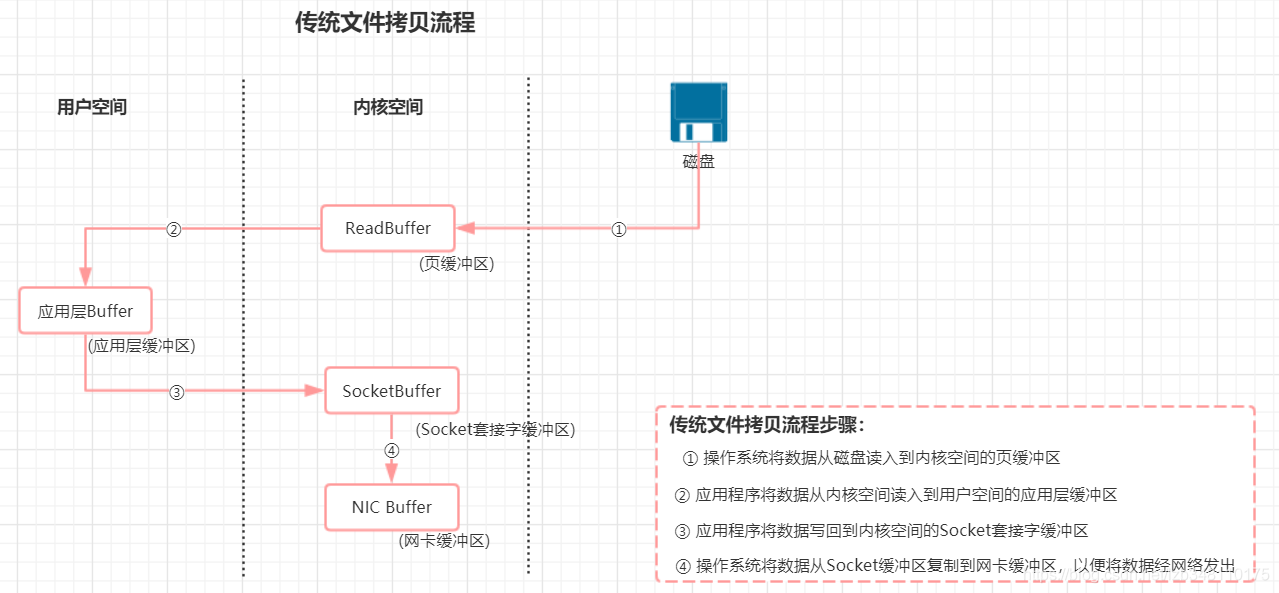
传统读写,涉及到 4 次数据的复制。但是这个过程中,数据完全没有变化,我们仅仅是想从磁盘把数据送到网卡。
那有没有办法不绕这一圈呢?让磁盘和网卡之类的外围设备直接访问内存,而不经过cpu?
有! 这就是DMA(Direct Memory Access 直接内存访问)。
6.2.2 DMA
DMA其实是由DMA芯片(硬件支持)来控制的。通过DMA控制芯片,可以让网卡等外部设备直接去读取内存,而不是由cpu来回拷贝传输。这就是所谓的零拷贝
目前计算机主流硬件基本都支持DMA,就包括我们的硬盘和网卡。
kafka就是调取操作系统的sendfile,借助DMA来实现零拷贝数据传输的

6.2.3 java实现
为加深理解,类比为java中的零拷贝:
-
在Java中的零拷贝是通过java.nio.channels.FileChannel中的transferTo方法来实现的
-
transferTo方法底层通过native调操作系统的sendfile
-
操作系统sendfile负责把数据从某个fd(linux file descriptor)传输到另一个fd
备注:linux下所有的设备都是一个文件描述符fd
代码参考:
File file = new File("0.log");
RandomAccessFile raf = new RandomAccessFile(file, "rw");
//文件通道,来源
FileChannel fileChannel = raf.getChannel();
//网络通道,去处
SocketChannel socketChannel = SocketChannel.open(new InetSocketAddress("1.1.1.1", 1234));
//对接上,通过transfer直接送过去
fileChannel.transferTo(0, fileChannel.size(), socketChannel);
6.3 分区一致性
6.3.1 水位值
1)先回顾两个值:
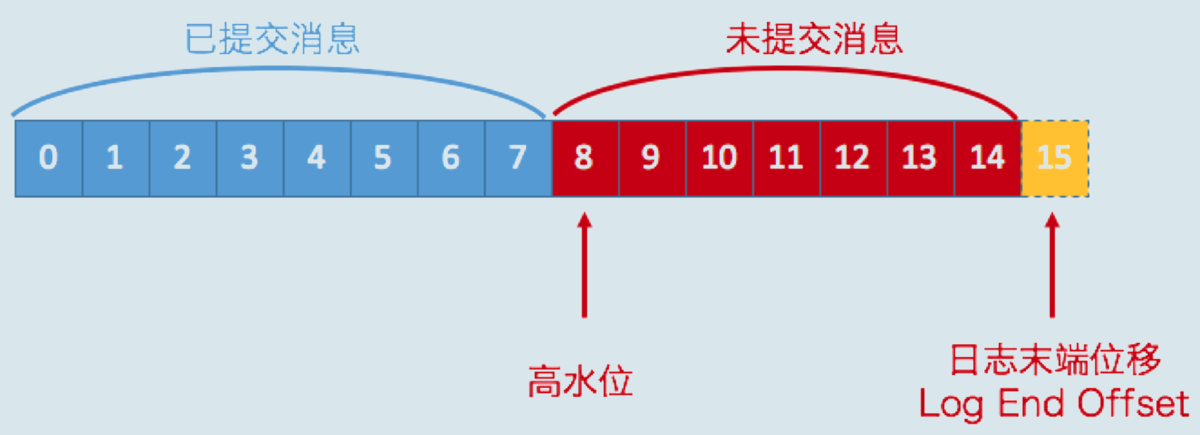
2)再看下几个值的存储位置:
注意!分区是有leader和follower的,最新写的消息会进入leader,follower从leader不停的同步
无论leader还是follower,都有自己的HW和LEO,存储在各自分区所在的磁盘上
leader多一个Remote LEO,它表示针对各个follower的LEO,leader又额外记了一份!
3)为什么这么做呢?
leader会拿这些remote值里最小的来更新自己的hw,具体过程我们详细往下看
6.3.2 同步原理
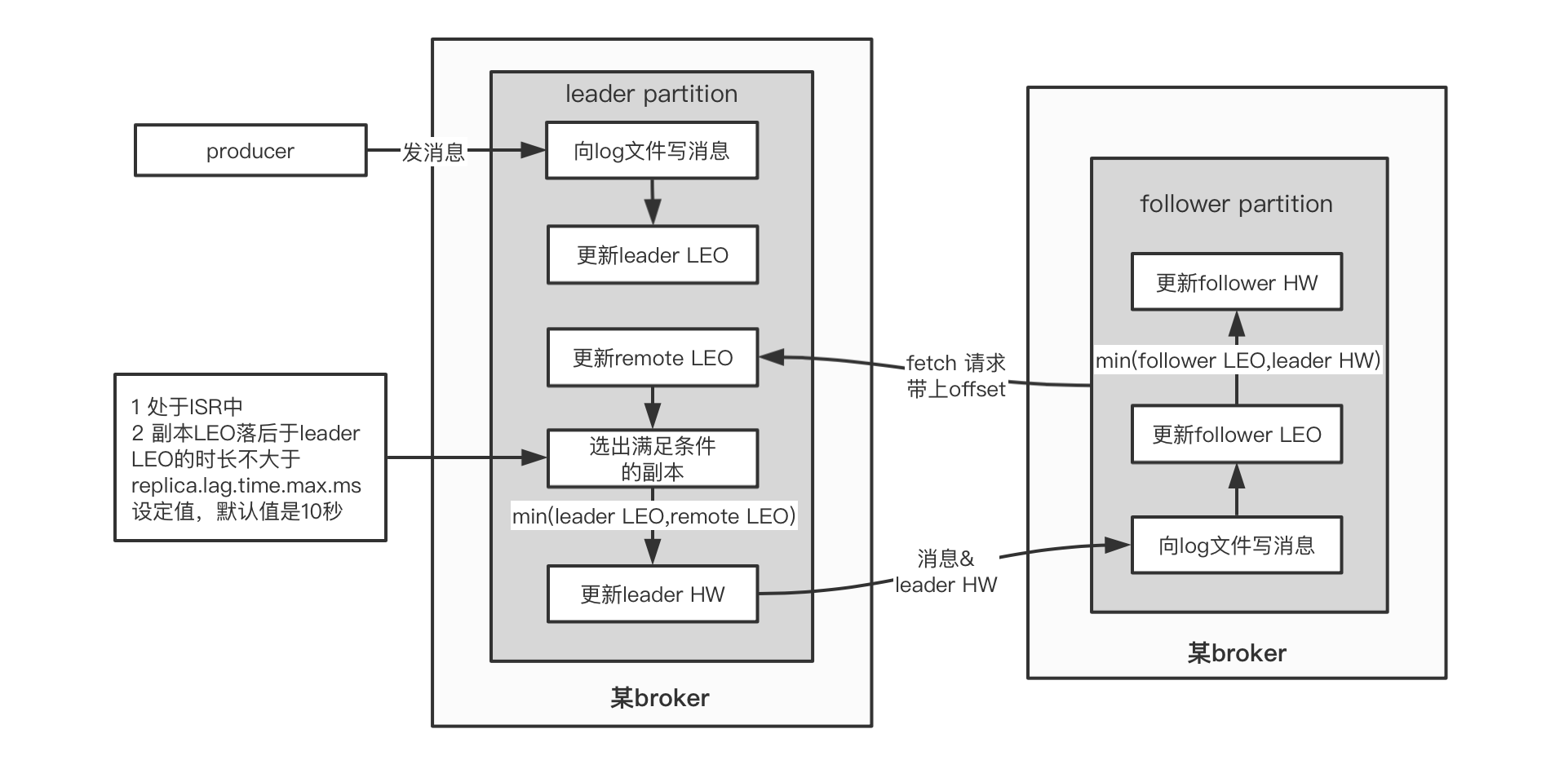
我们来看这几个值是如何更新的:
1)leader.LEO
这个很简单,每次producer有新消息发过来,就会增加
2)其他值
另外的4个值初始化都是 0
他们的更新由follower的fetch(同步消息线程)得到的数据来决定!
如果把fetch看做是leader上提供的方法,由follower远程请求调用,那么它的伪代码大概是这个样子:
//java伪代码!
//follower端的操作,不停的请求从leader获取最新数据
class Follower{
private List<Message> messages;
private HW hw;
private LEO leo;
@Schedule("不停的向leader发起同步请求")
void execute(){
//向leader发起fetch请求,将自己的leo传过去
//leader返回leo之后最新的消息,以及leader的hw
LeaderReturn lr = leader.fetch(this.leo) ;
//存消息
this.messages.addAll(lr.newMsg);
//增加follower的leo值
this.leo = this.leo + lr.newMsg.length;
//比较自己的leo和leader的hw,取两者小的,作为follower的hw
this.hw = min(this.leo , lr.leaderHW);
}
}
//leader返回的报文
class LeaderReturn{
//新增的消息
List<Messages> newMsg;
//leader的hw
HW leaderHW;
}
//leader在接到follower的fetch请求时,做的逻辑
class Leader{
private List<Message> messages;
private LEO leo;
private HW hw;
//Leader比follower多了个Remote!
//注意!如果有多个副本,那么RemoteLEO也有多个,每个副本对应一个
private RemoteLEO remoteLEO;
//接到follower的fetch请求时,leader做的事情
LeaderReturn fetch(LEO followerLEO){
//根据follower传过来的leo,来更新leader的remote
this.remoteLEO = followerLEO ;
//然后取ISR(所有可用副本)的最小leo作为leader的hw
this.hw = min(this.leo , this.remoteLEO) ;
//从leader的消息列表里,查找大于follower的leo的所有新消息
List<Message> newMsg = queryMsg(followerLEO) ;
//将最新的消息(大于follower leo的那些),以及leader的hw返回给follower
LeaderReturn lr = new LeaderReturn(newMsg , this.hw)
return lr;
}
}
6.3.3 Leader Epoch
1)产生的背景
0.11版本之前的kafka,完全借助hw作为消息的基准,不管leo。
发生故障后的规则:
- follower故障再次恢复后,从磁盘读取hw的值并从hw开始剔除后面的消息,并同步leader消息
- leader故障后,新当选的leader的hw作为新的分区hw,其余节点按照此hw进行剔除数据,并重新同步
- 上述根据hw进行数据恢复会出现数据丢失和不一致的情况,下面分开来看
假设:
我们有两个副本:leader(A),follower(B)
场景一:丢数据
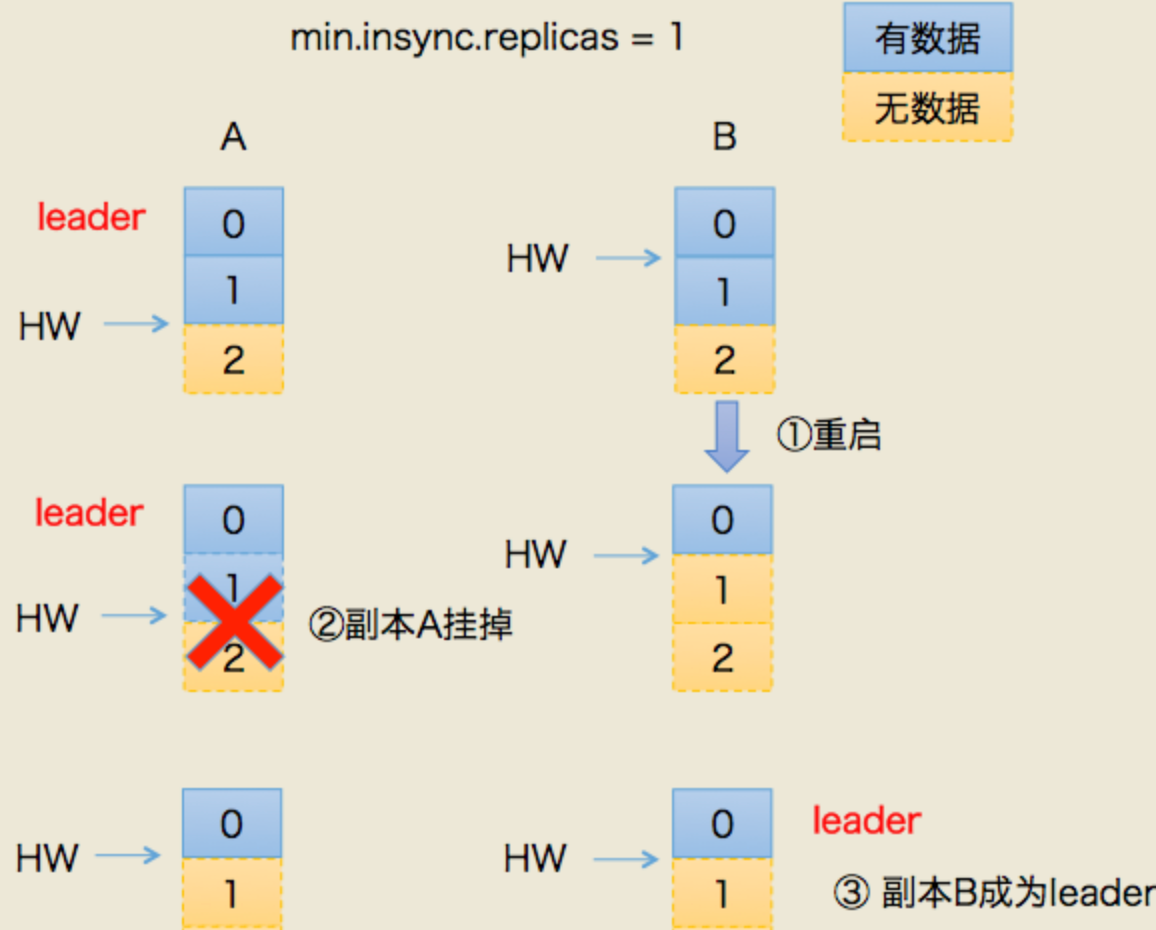
- 某个时间点B挂了。当它恢复后,以挂之前的hw为准,设置 leo = hw
- 这就造成一个问题:现实中,leo 很可能是 大于 hw的。leo被回退了!
- 如果这时候,恰恰A也挂掉了。kafka会重选leader,B被选中。
- 过段时间,A恢复后变成follower,从B开始同步数据。
- 问题来了!上面说了,B的数据是被回退过的,以它为基准会有问题
- 最终结果:两者的数据都发生丢失,没有地方可以找回!
场景二:数据不一致
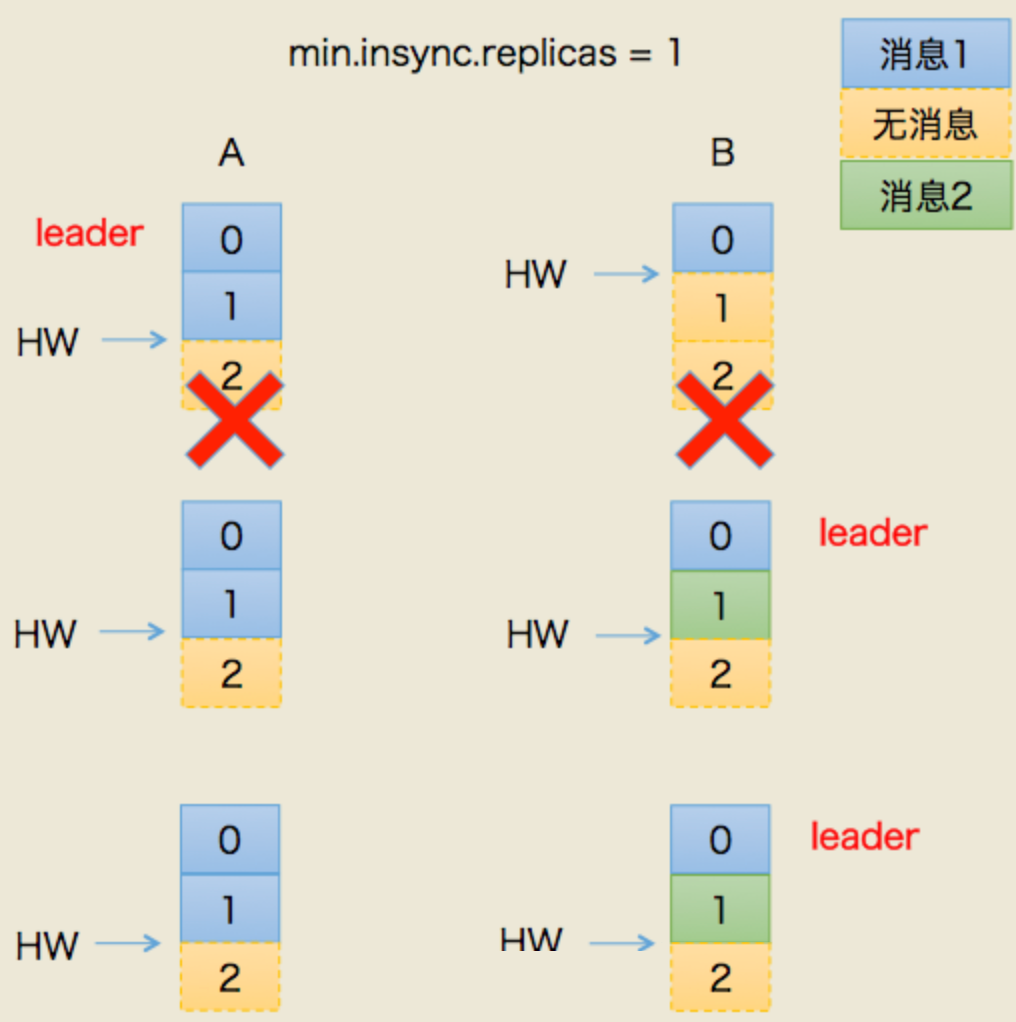
- 这次假设AB全挂了。比较惨
- B先恢复。但是它的hw有可能挂之前没从A同步过来(原来A是leader)
- 我们假设,A.hw = 2 , B.hw = 1
- B恢复后,集群里只有它自己,所以被选为leader,开始接受新消息
- B.hw上涨,变成2
- 然后,A恢复,原来A.hw = 2 ,恢复后以B的hw,也就是2为基准开始同步。
- 问题来了!B当leader后新接到的2号消息是不会同步给A的,A一直保留着它当leader时的旧数据
- 最终结果:数据不一致了!
2)改进思路
0.11之后,kafka改进了hw做主的规则,这就是leader epoch
leader epoch给leader节点带了一个版本号,类似于乐观锁的设计。
它的思想是,一旦发生机器故障,重启之后,不再机械的将leo退回hw
而是借助epoch的版本信息,去请求当前leader,让它去算一算leo应该是什么
3)实现原理
对比上面丢数据的问题:
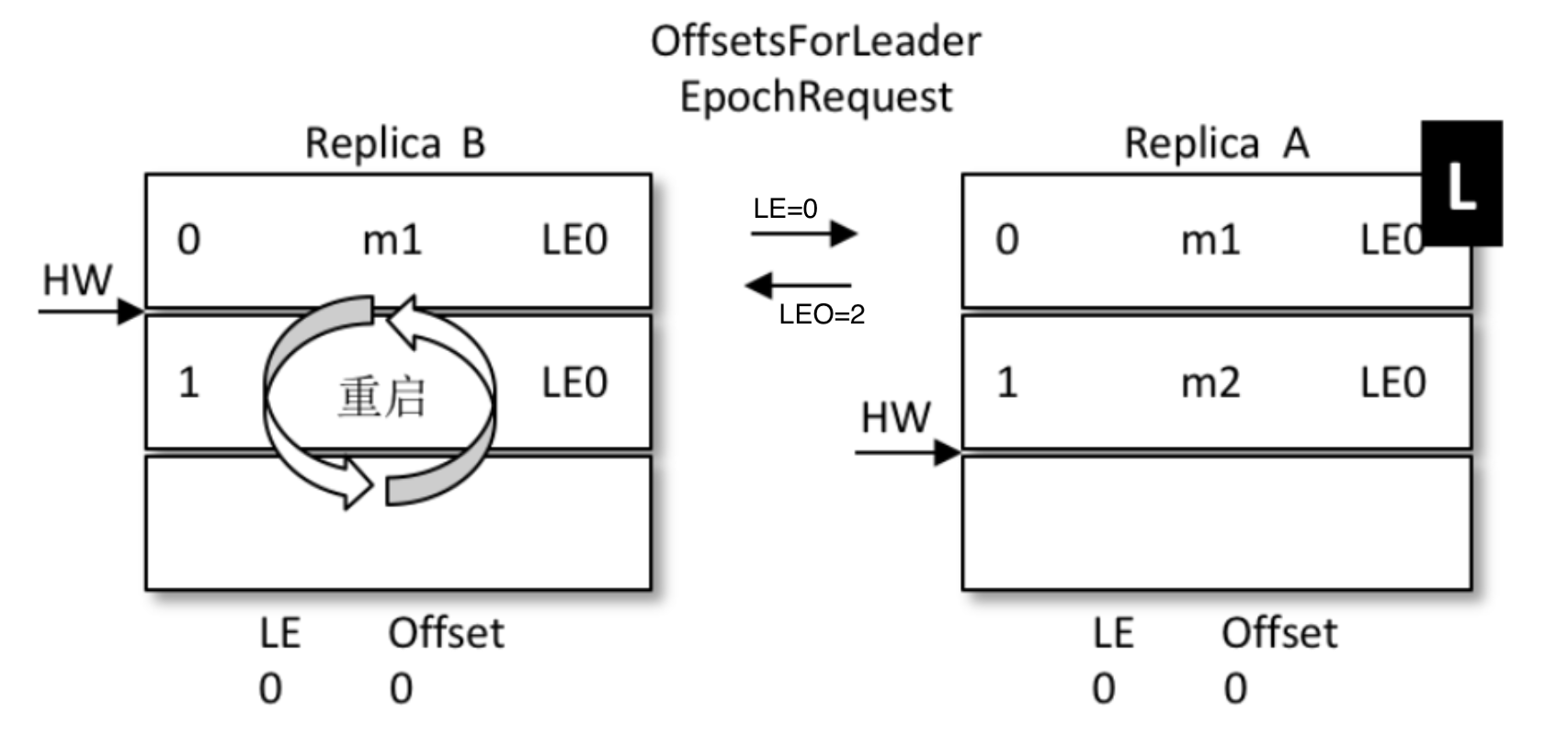
- A为(leo=2 , hw=2),B为(leo=2 , hw=1)
- B重启,但是B不再着急将leo打回hw,而是发起一个Epoch请求给当前leader,也就是A
- A收到LE=0后,发现和自己的LE一样,说明B在挂掉前后,leader没变,都是A自己
- 那么A就将自己的leo值返回给B,也就是数字2
- B收到2后和自己的leo比对取较小值,发现也是2,那么不再退回到hw的1
- 没有回退,也就是信息1的位置没有被覆盖,最大程度的保护了数据
- 如果和上面一样的场景,A挂掉,B被选为leader
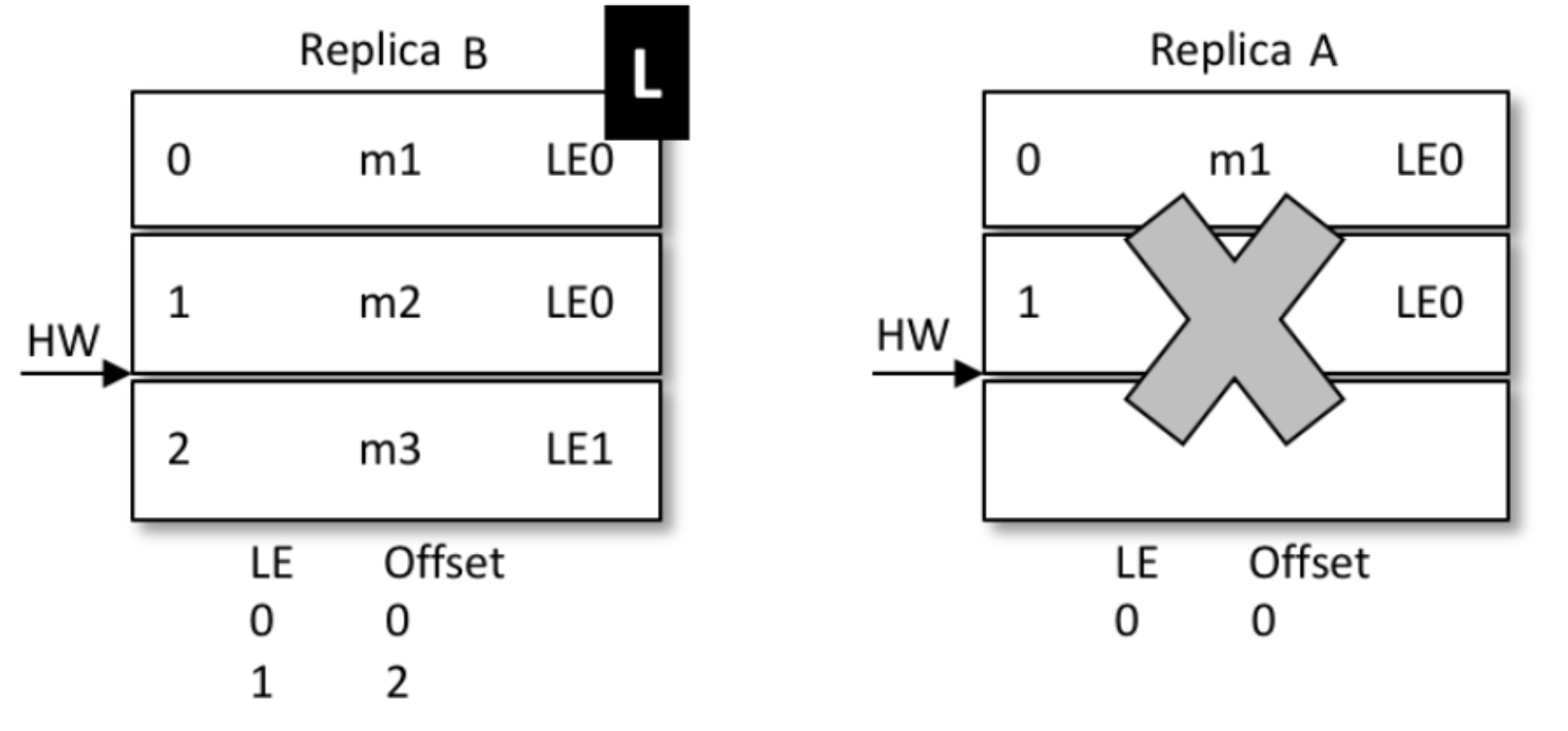
-
那么A再次启动时后,从B开始同步数据
-
因为B之前没有回退,1号信息得到了保留
-
同时,B的LE(epoch号码)开始增加,从0变成1,offset记录为B当leader时的位置,也就是2
-
A传过来的epoch为0,B是1,不相等。那么取大于0的所有epoch里最小的
(现实中可能发生了多次重新选主,有多条epoch)
-
其实就是LE=1的那条。现实中可能有多条。并找到它对应的offset(也就是2)给A返回去
-
最终A得到了B同步过来的数据
再来看一致性问题的解决:

-
还是上面的场景,AB同时挂掉,但是hw还没同步,那么A.hw=2 , B.hw=1
-
B先启动被选成了leader,新leader选举后,epoch加了一条记录(参考下图,LE=1,这时候offset=1)
-
表示B从1开始往后继续写数据,新来了条信息,内容为m3,写到1号位
-
A启动前,集群只有B自己,消息被确认,hw上涨到2,变成下面的样子
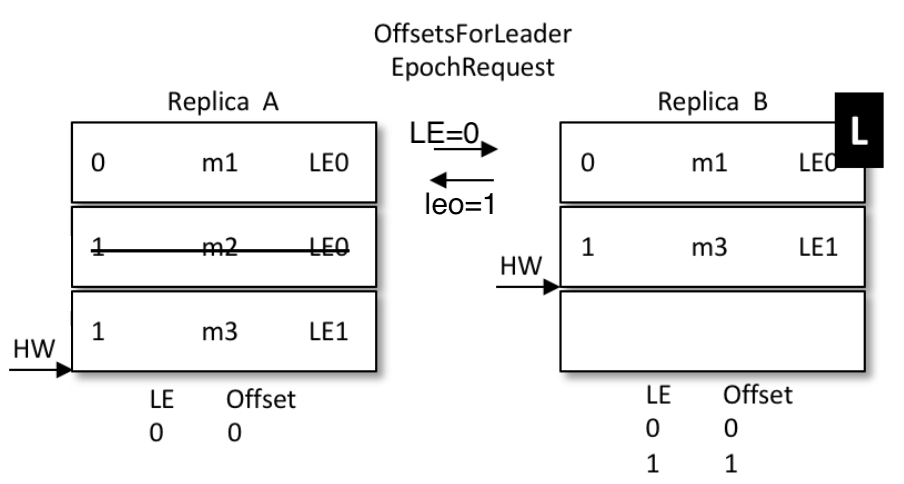
-
A开始恢复,启动后向B发送epoch请求,将自己的LE=0告诉leader,也就是B
-
B发现自己的LE不同,同样去大于0的LE里最小的那条,也就是1 , 对应的offset也是1,返回给A
-
A从1开始同步数据,将自己本地的数据截断、覆盖,hw上升到2
-
那么最新的写入的m3从B给同步到了A,并覆盖了A上之前的旧数据m2
-
结果:数据保持了一致
附:epochRequest的详细流程图
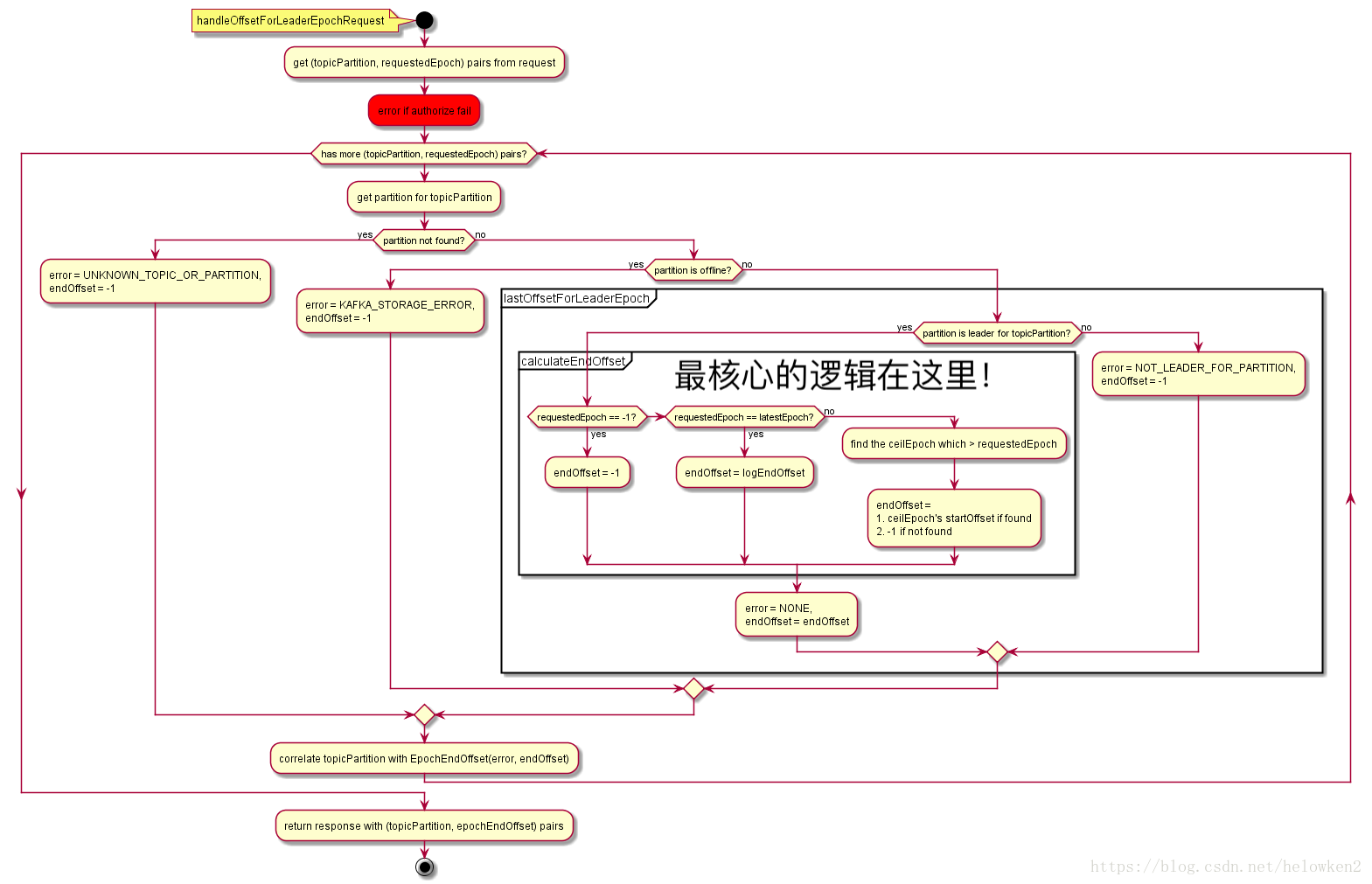
本文由传智教育博学谷 – 狂野架构师教研团队发布
如果本文对您有帮助,欢迎关注和点赞;如果您有任何建议也可留言评论或私信,您的支持是我坚持创作的动力
转载请注明出处!










