
前言
嗨喽,大家好呀~这里是爱看美女的茜茜呐

小姐姐你们喜欢吗?反正我是喜欢的,所以我决定!!
今天采集小姐姐视频~保存下来供我欣赏

环境使用:
-
Python 3.8
-
Pycharm
模块使用:
- import requests >>> pip install requests
内置模块 你安装好python环境就可以了
-
import re
-
import json
如果安装python第三方模块:
-
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
-
在pycharm中点击Terminal(终端) 输入安装命令
基本思路流程: <实现采集案例基本 通用>
一. 数据来源分析
-
明确我们的需求 https://www.acfun.cn/v/ac35510357 这个视频内容
-
分析我们视频内容来自于哪里
通过开发者工具进行抓包分析:
-
F12 或者 鼠标右键点击检查
-
分析数据在那个数据包里面 这个网站数据是不是m3u8需要自己判断
m3u8 好处是什么, 你看多少内容就给你加载多少内容, 你看三秒就给你加载三秒, 绿色双人爱情…..<>
正常的视频内容: MP4 2分钟18秒
m3u8 分片段 —> 分为很多小片段 <ts文件>, 一个小片段只有几秒钟的时间
我想要获取整个视频内容, 获取所有ts文件, 所有ts文件又保存在m3u8的文件里面
想要视频内容 —> 分片段 ts文件 —> m3u8文件里面 —> 在网页源代码里面
二. 代码实现步骤: 爬虫基本四大步骤:
-
发送请求, 对于视频详情页url地址发送请求
-
获取数据, 获取服务器返回响应数据
-
解析数据, 提取我们要的 m3u8文件链接
-
发送请求, 对于 m3u8文件链接 发送请求
-
获取数据, 获取服务器返回响应数据
-
解析数据, 提取我们要的 所有ts文件链接
-
保存数据, 把视频片段全部保存下载, 合成为一个整体视频内容

代码
导入模块
# 导入数据请求模块 ---> 第三方模块 需要 在cmd里面进行 pip install requests import requests # 导入re正则模块 ---> 内置模块 不需要安装 import re # 导入json模块 ---> 内置模块 不需要安装 import json # 导入格式化输出模块 ---> 内置模块 不需要安装 from pprint import pprint # 导入进度条模块 ---> 第三方模块 需要 在cmd里面进行 pip install tqdm from tqdm import tqdm # 导入tk GUI模块 import tkinter as tk import tkinter.messagebox
更多资料获取加Q裙:261823976 点击蓝字加入【python学习裙】

def get_response(html_url): """ 发送请求函数 :param html_url: 请求链接 :return: 响应对象 """ # 伪装浏览器 headers ---> 开发者工具里面复制粘贴 headers = { # 浏览器基本身份信息 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36' } # 发送请求 <Response [200]> 响应对象 response = requests.get(url=html_url, headers=headers) return response def get_video_info(video_id): """ 获取信息数据 :param video_id: 视频ID :return: 视频数据 """ video_url = f'https://www.acfun.cn/v/ac{video_id}' response = get_response(video_url) # 提取视频标题 title = re.findall('"title":"(.*?)",', response.text)[1] # 获取m3u8 html_data = re.findall('window.pageInfo = window.videoInfo = (.*?);', response.text)[0] # 转换数据类型 json_data = json.loads(html_data) # 字典取值, 键值对 ---> 根据冒号左边的内容[键], 提取冒号右边的内容[值] m3u8_url = \ json.loads(json_data['currentVideoInfo']['ksPlayJson'])['adaptationSet'][0]['representation'][0]['backupUrl'][0] # 4. 发送请求, 对于 m3u8文件链接 发送请求 5. 获取数据, 获取服务器返回响应数据 m3u8_data = get_response(m3u8_url).text # 6. 解析数据 m3u8_data = re.sub('#E.*', '', m3u8_data).split() # 列表推导式 ts_url_list = ['https://ali-safety-video.acfun.cn/mediacloud/acfun/acfun_video/' + ts for ts in m3u8_data] return title, ts_url_list def save(title, ts_url): """ 保存数据 :param title: 视频标题 :param ts_url: ts链接 :return: """ ts_content = get_response(ts_url).content with open('video\\' + title + '.mp4', 'ab') as f: f.write(ts_content) def main(): """ 主函数 :param video_id: :return: """ video_id = Va.get() # 获取视频数据信息 title, ts_url_list = get_video_info(video_id) for ts_url in tqdm(ts_url_list): save(title, ts_url) tk.messagebox.showinfo(title='温馨提示', message=f'{title}下载完成') if __name__ == '__main__': # main('35556211') # 实例化对象 root = tk.Tk() # 设置标题 root.title('小视频下载') # 设置大小 root.geometry('424x115+200+200') # 设置可变变量 Va = tk.StringVar() # 设置文字 tk.Label(root, text='仅提供学习交流', font=('黑体', 15)).grid(row=0, column=2) tk.Label(root, text='输入视频ac号: ', font=('黑体', 15)).grid(row=1, column=1) # 设置输入框 tk.Entry(root, textvariable=Va).grid(row=1, column=2) # 设置按钮 tk.Button(root, text='下载', font=('黑体'), command=main).grid(row=1, column=3) # 显示窗口 root.mainloop()
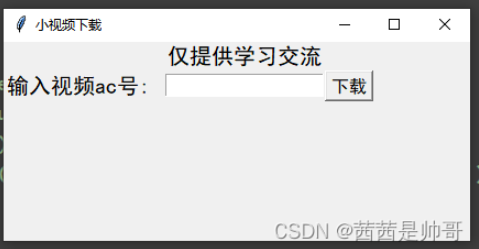





尾语
感谢你观看我的文章呐~本次航班到这里就结束啦
希望本篇文章有对你带来帮助 ,有学习到一点知识~
躲起来的星星也在努力发光,你也要努力加油(让我们一起努力叭)。
最后,博主要一下你们的三连呀(点赞、评论、收藏),不要钱的还是可以搞一搞的嘛~
不知道评论啥的,即使扣个6666也是对博主的鼓舞吖 感谢











