
索引生命周期管理 (Index cycle management: ILM) 是在 Elasticsearch 6.7 版正式推出的一项功能,它是 Elasticsearch 的一部分,主要用来帮助管理索引。
1、简介
如果你要处理时间序列数据,则不想将所有内容连续转储到单个索引中。 取而代之的是,你可以定期将数据滚动到新索引,以防止数据过大而又缓慢又昂贵。 随着索引的老化和查询频率的降低,你可能会将其转移到价格较低的硬件上,并减少分片和副本的数量。
要在索引的生命周期内自动移动索引,可以创建策略来定义随着索引的老化对索引执行的操作,这样可以确保所有索引具有相似的大小。
ILM 由一些策略(policies)组成,而这些策略可以触发一些 actions。这些 actions 可以为:
| Action | Description |
| rollover | 创建一个新的索引,基于数据的时间跨度,大小及文档的多少 |
| shrink | 减少 primary shards 的数目 |
| force merge | 合并 shard 的 segments |
| freeze | 针对鲜少使用的索引进行冻结以节省内存 |
| delete | 永久地删除一个索引 |
索引生命周期由五个阶段(phases)组成:hot,warm,cold,frozen 及 delete。每个阶段有一组可用的 actions。这些 actions 由上面的 actions 中的一些组成。把这些阶段和相应的 actions 一起组合起来就形成了一个策略(policy)。我们可以通过 API 的形式或者直接在 Kibana 中使用 UI 的形式来创建这些 policies。
ILM 策略实例:
在 hot 阶段,你可能 rollover 一个 alias 从而每两个星期就生成一个新的索引,避免太大的索引数据。在这个阶段你可以做导入数据,并允许繁重的搜索。
在 warm 阶段,你可能把索引变成 read-only,并把索引保留于这个阶段一个星期。在这个阶段,不可以导入数据,但是可以进行适度的搜索。
在 cold 阶段,你可能 freeze 索引,并减少 replica 的数量,并保留于这个阶段三个星期。在这个阶段,不可以导入数据,但是可以进行极其少量的搜索,
在 delete 阶段,只有一个动作可以选择。比如你可以删除超过 6 个星期的索引数据以节省成本。
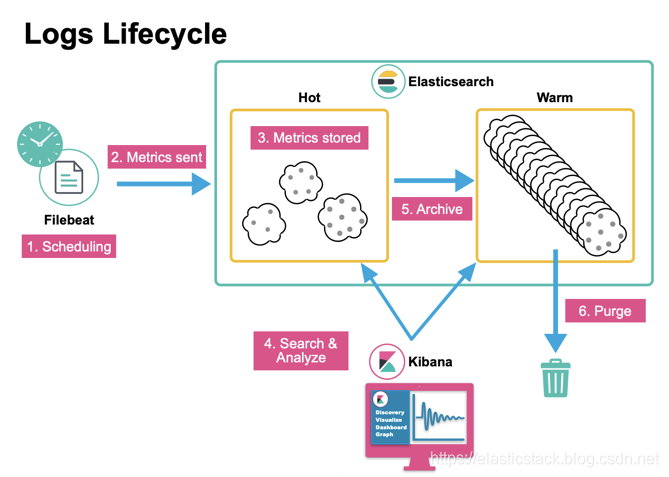
索引在 Elasticsearch 中的生命周期:
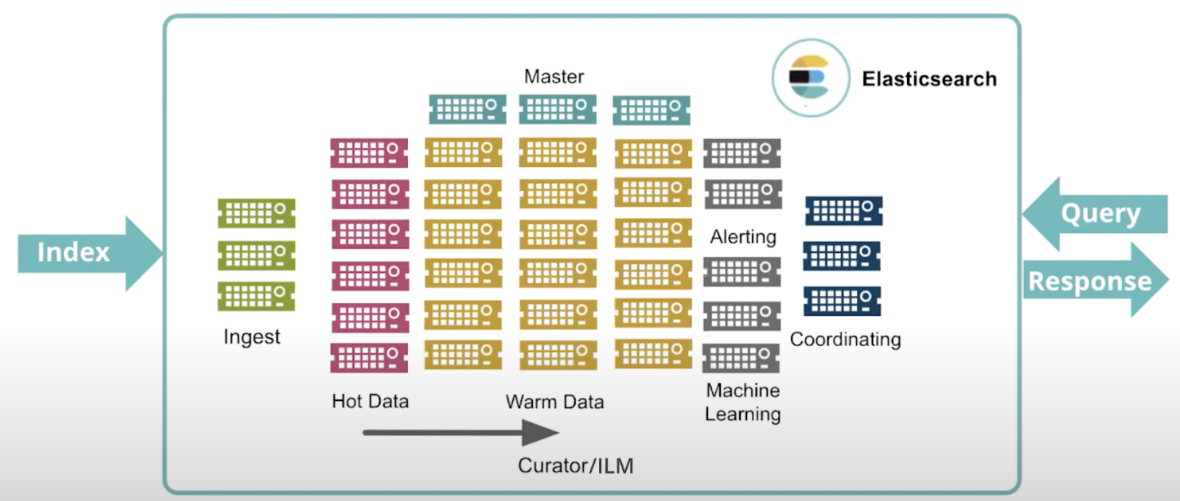
针对一个超大规模的集群:
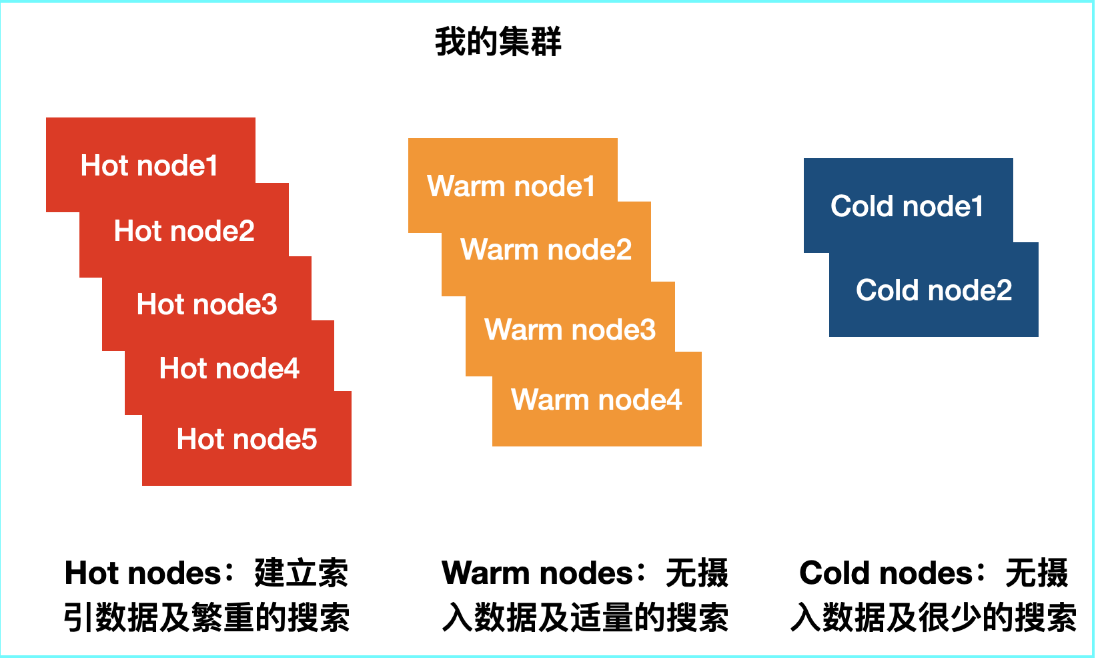
各节点职责:
2、生命周期管理演示
2.1、启动 Elasticsearch 集群
启动三个节点(10.49.196.10、10.49.196.11、10.49.196.12)的集群,其中两个为 hot 节点(存放 hot 阶段的数据),一个为 warm 节点(存放 warm 阶段的数据)。
在 10.49.196.10、10.49.196.11 上运行:
bin/elasticsearch -d -E node.attr.data=hot
在 10.49.196.12 上运行:
bin/elasticsearch -d -E node.attr.data=warm
查看 node 属性信息:
GET _cat/nodeattrs?v

2.2、创建 ILM policy
PUT _ilm/policy/my_policy { "policy": { "phases": { "hot": { "actions": { "rollover": { "max_size": "10mb", "max_age": "1d", "max_docs": 5 } } }, "warm": { "min_age": "5m", "actions": { "shrink": { "number_of_shards": 1 }, "allocate": { "number_of_replicas": 0, "require": { "data": "warm" } } } }, "delete": { "min_age": "10m", "actions": { "delete": {} } } } } }
这里定义的 policy 意思为:
热阶段
索引创建 1 天后、索引大小达到 10MB 或 索引文档数达到 5(符合任何一个即可),该索引将滚动更新,系统将创建一个新索引。该新索引将重新启动策略,而当前的索引(刚刚滚动更新的索引)将在滚动更新后等待 5 分钟进入温阶段。
温阶段
索引进入温阶段后,ILM 会将索引收缩到 1 个分片 0 个副本,通过分配操作将索引移动到温节点。完成该操作后,索引将再等待 5 分钟 (时间都是从滚动跟新算起,10 – 5 = 5)后进入删除阶段。
删除阶段
删除阶段具有用于删除索引的删除操作。在删除阶段,您将始终需要有一个 min_age 条件,以允许索引在给定时段内待在热、温或冷阶段。
2.3、创建 Index template
PUT _template/my_template { "index_patterns": ["test-*"], "settings": { "index.lifecycle.name": "my_policy", "index.lifecycle.rollover_alias": "test-alias", "index.routing.allocation.require.data": "hot", "index": { "number_of_shards": 2, "number_of_replicas": 1 } }, "mappings": { "properties": { "age": { "type": "integer" }, "name": { "type": "keyword" }, "poems": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "about": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" }, "success": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word" } } } }
所有以 test- 开头的 index 都需要遵循这个规律。这里定义了 rollover 的 alias 为 “test-alias”。需要注意的是 “index.routing.allocation.require.data”: “hot”,这定义了我们需要 indexing 的 node 的 data 属性是 hot。
2.4、定义 Index alias
PUT test-000001 { "aliases": { "test-alias": { "is_write_index": true } } }
这里定义了一个叫做 test-alias 的 alias,它指向 test-00001 索引。注意这里的 is_write_index 为 true。如果有 rollover 发生时,这个alias会自动指向最新 rollover 的 index。
使用 elasticsearch-head 查看该索引:

2.5、新增数据
POST test-alias/_bulk {"index":{"_id":"1"}} {"age": 30,"name": "李白1","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"} {"index":{"_id":"2"}} {"age": 30,"name": "李白2","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"} {"index":{"_id":"3"}} {"age": 30,"name": "李白3","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"} {"index":{"_id":"4"}} {"age": 30,"name": "李白4","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"} {"index":{"_id":"5"}} {"age": 30,"name": "李白5","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"} {"index":{"_id":"6"}} {"age": 30,"name": "李白6","poems": "静夜思","about": "字太白","success": "创造了古代浪漫主义文学高峰、歌行体和七绝达到后人难及的高度"}
2.5、rollover
已经有超过 5 个文档了,将会 rollover;rollover 扫描间隔默认时 10 分钟,可以通过修改 indices.lifecycle.poll_interval 参数来改变默认的间隔时间。
PUT _cluster/settings { "transient": { "indices.lifecycle.poll_interval": "30s" } }
rollover 后会生成新的索引:

2.6、进入 warm 阶段
rollover 后,索引 test-000001 等待 5 分钟左右后将会进入 warm 阶段。
rollover 后的情况:
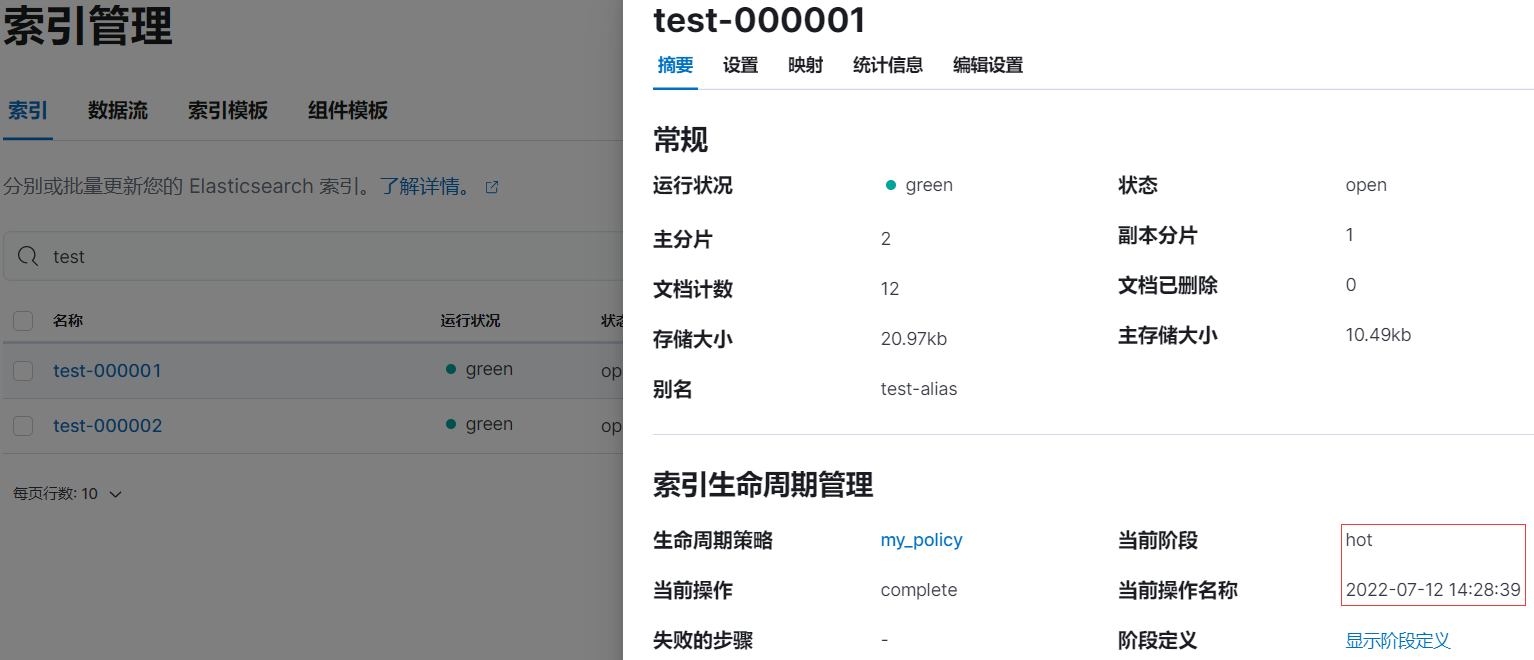
rollover 后等待 5 分钟左右后,索引 test-000001 已被重命名为 shrink-so7u-test-000001:
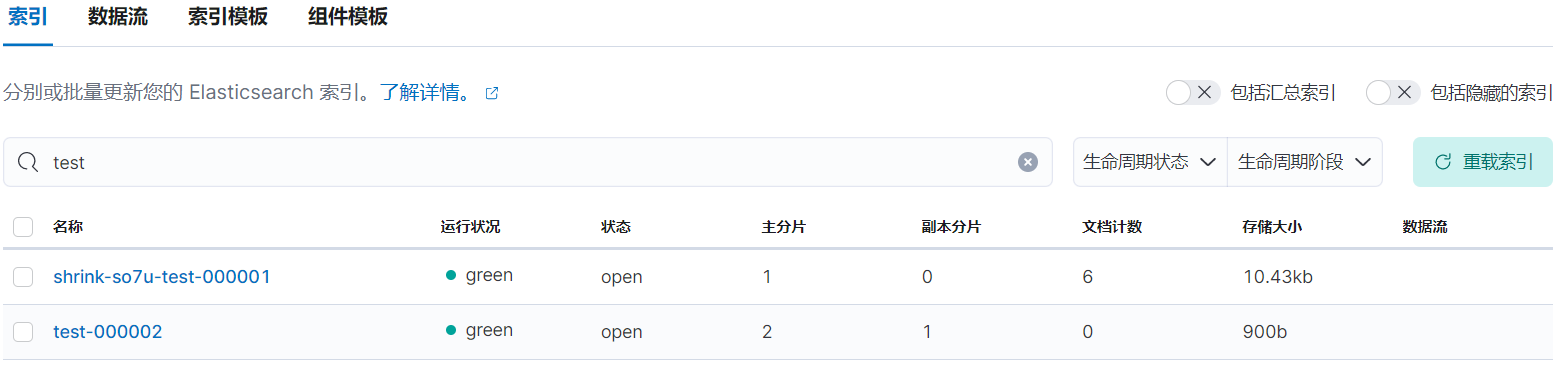
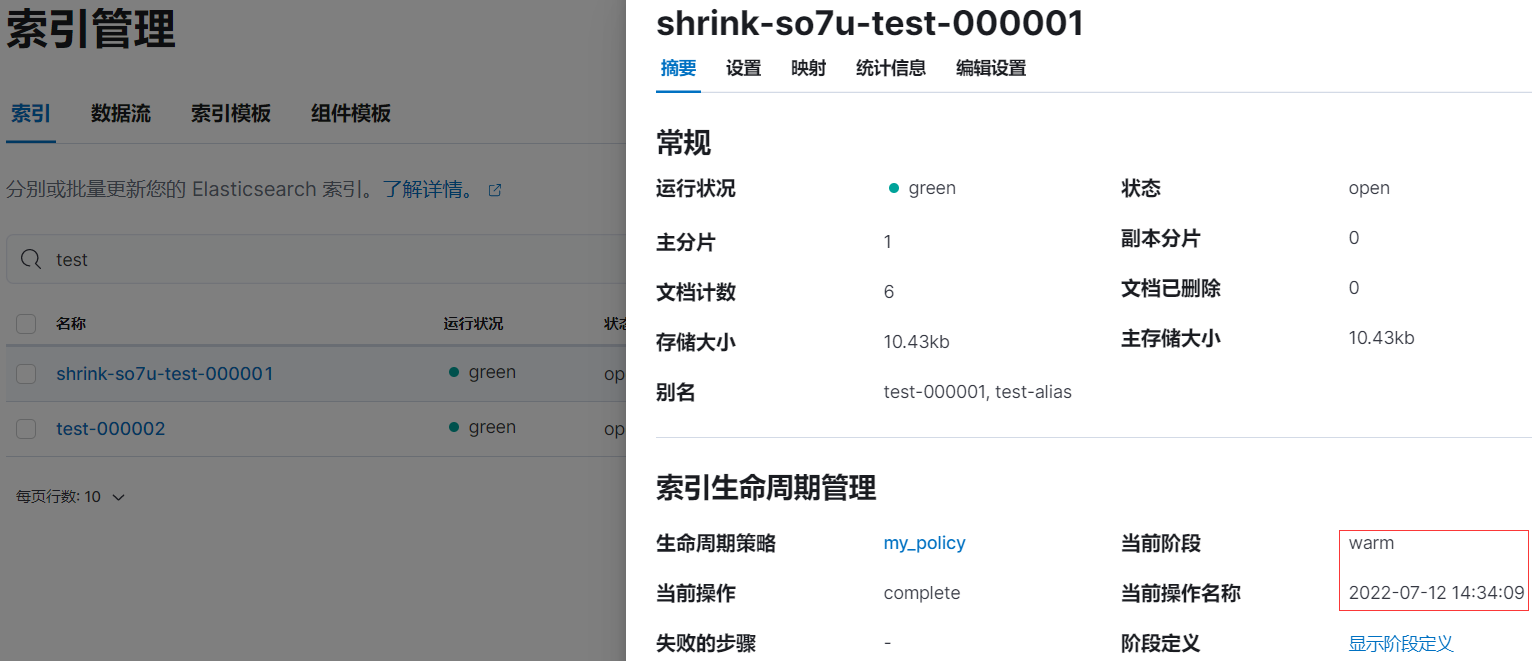
2.7、进入 delete 阶段
在 warm 阶段再等待 5 分钟(10m – 5m)左右后, shrink-so7u-test-000001 进入 delete 阶段,索引将被删除。
参考:
1、https://elasticstack.blog.csdn.net/article/details/102728987
2、https://elasticstack.blog.csdn.net/article/details/102856967










