
大家好,又见面了。
今天我们一起聊一聊JAVA中的函数式接口。那我们首先要知道啥是函数式接口、它和JAVA中普通的接口有啥区别?其实函数式接口也是一个Interface类,是一种比较特殊的接口类,这个接口类有且仅有一个抽象方法(但是可以有其余的方法,比如default方法)。
当然,我们看源码的时候,会发现JDK中提供的函数式接口,都会携带一个 @FunctionalFunction注解,这个注释是用于标记此接口类是一个函数式接口,但是这个注解并非是实现函数式接口的必须项。说白了,加了这个注解,一方面可以方便代码的理解,告知这个代码是按照函数式接口来定义实现的,另一方面也是供编译器协助检查,如果此方法不符合函数式接口的要求,直接编译失败,方便程序员介入处理。
所以归纳下来,一个函数式接口应该具备如下特性:
- 是一个JAVA interface类
- 有且仅有1个公共抽象方法
- 有
@FunctionalFunction标注(可选)
比如我们在多线程场景中都很熟悉的Runnable接口,就是个典型的函数式接口,符合上面说的2个特性:
@FunctionalInterface
public interface Runnable {
/**
* When an object implementing interface <code>Runnable</code> is used
* to create a thread, starting the thread causes the object's
* <code>run</code> method to be called in that separately executing
* thread.
* <p>
* The general contract of the method <code>run</code> is that it may
* take any action whatsoever.
*
* @see java.lang.Thread#run()
*/
public abstract void run();
}
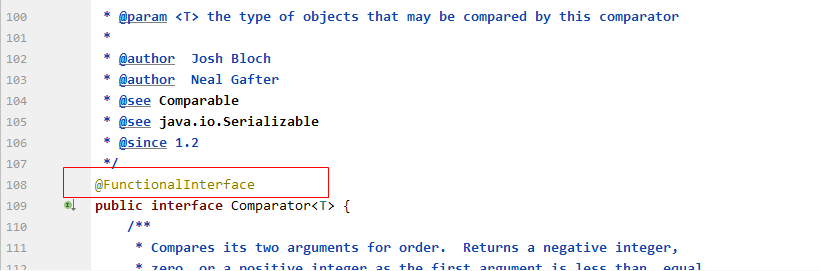
但是,我们在看JDK源码的时候,也会看到有些函数式接口里面有多个抽象方法。比如JDK中的 Comparator接口的定义如下:
@FunctionalInterface
public interface Comparator<T> {
int compare(T o1, T o2);
boolean equals(Object obj);
// 其他方法省略...
}
可以看到,Comparator接口里面提供了 compare和 equals两个抽象方法。这是啥原因呢?回答这个问题前,我们可以先来做个试验。
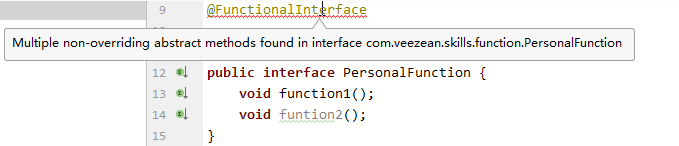
我们自己定义一个函数式接口,里面提供两个抽象方法测试一下,会发现IDEA中直接就提示编译失败了:
同样是这个自定义的函数式接口,我们修改下里面的抽象方法名称,改为 equals方法,会发现这样就不报错了:

在IDEA中可能更容易看出端倪来,在上面的图中,注意到12行代码前面那个 @符号了吗?我们换种写法,改为如下的方式,原因就更加清晰了:
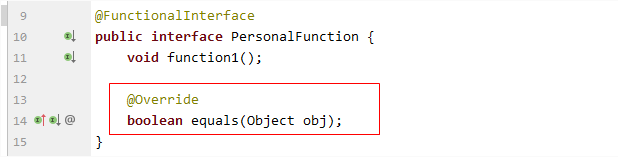
原来,这个 equals方法,其实是继承自父类的方法,因为所有的类最终都是继承自Object类,所以 equals方法只能算是对父类接口的一个覆写,而不算是此接口类自己的抽象方法,所以此方法里面实际上还是只有 1个抽象方法,并没有违背函数式接口的约束条件。

函数式接口在JDK中的大放异彩
JDK源码 java.util.function包下面提供的一系列的预置的函数式接口定义:

部分使用场景比较多的函数式接口的功能描述归纳如下:
| 接口类 | 功能描述 |
|---|---|
| Runnable | 直接执行一段处理函数,无任何输出参数,也没有任何输出结果。 |
Supplier<T> |
执行一段处理函数,无任务输入参数,返回一个T类型的结果。与Runnable的区别在于Supplier执行完之后有返回值。 |
Consumer<T> |
执行一段处理函数,支持传入一个T类型的参数,执行完没有任何返回值。 |
| BiConsumer<T, U> | 与Consumer类型相似,区别点在于BiConsumer支持传入两个不同类型的参数,执行完成之后依旧没有任何返回值。 |
| Function<T, R> | 执行一段处理函数,支持传入一个T类型的参数,执行完成之后,返回一个R类型的结果。与Consumer的区别点就在于Function执行完成之后有输出值。 |
| BiFunction<T, U, R> | 与Function相似,区别点在于BiFunction可以传入两个不同类型的参数,执行之后可以返回一个结果。与BiConsumer也很类似,区别点在于BiFunction可以有返回值。 |
UnaryOperator<T> |
传入一个参数对象T,允许对此参数进行处理,处理完成后返回同样类型的结果对象T。继承Function接口实现,输入输出对象的类型相同。 |
BinaryOperator<T> |
允许传入2个相同类型的参数,可以对参数进行处理,最后返回一个仍是相同类型的结果T。继承BiFunction接口实现,两个输入参数以及最终输出结果的对象类型都相同。 |
Predicate<T> |
支持传入一个T类型的参数,执行一段处理函数,最后返回一个布尔类型的结果。 |
| BiPredicate<T, U> | 支持传入2个相同类型T的参数,执行一段处理函数,最后返回一个布尔类型的结果。 |
JDK中 java.util.function 包内预置了这么多的函数式接口,很多场景下其实都是给JDK中其它的类或者方法中使用的,最典型的就是Stream了——可以说有一大半预置的函数式接口类,都是为适配Stream相关能力而提供的。也正是基于函数式接口的配合使用,才是使得Stream的灵活性与扩展性尤其的突出。
下面我们一起来看几个Stream的方法实现源码,来感受下函数式接口使用的魅力。
比如,Stream中的 filter过滤操作,其实就是传入一个元素对象,然后经过一系列的处理与判断逻辑,最后需要给定一个boolean的结果,告知filter操作是应该保留还是丢弃此元素,所以filter方法传入的参数就是一个 Predicate函数式接口的具体实现(因为Predicate接口的特点就是传入一个T对象,输出一个boolean结果):
/**
* Returns a stream consisting of the elements of this stream that match
* the given predicate.
*/
Stream<T> filter(Predicate<? super T> predicate);
又比如,Stream中的 map操作,是通过遍历的方式,将元素逐个传入函数中进行处理,并支持输出为一个新的类型对象结果,所以map方法要求传入一个 Function函数式接口的具体实现:
/**
* Returns a stream consisting of the results of applying the given
* function to the elements of this stream.
*/
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
再比如,Stream中的终止操作 forEach方法,其实就是通过迭代的方式去对元素进行逐个处理,最终其并没有任何返回值生成,所以forEach方法定义的时候,要求传入的是一个 Consumer函数式接口的具体实现:
/**
* Performs an action for each element of this stream.
*/
void forEach(Consumer<? super T> action);
具体使用的时候,每个方法中都需要传入具体函数式接口的实现逻辑,这个时候结合Lambda表达式,可以让代码更加的简洁干练(不熟悉的话,也可能会觉得更加晦涩难懂~),比如:
public void testStreamUsage(@NotNull String sentence) {
Arrays.stream(sentence.split(" "))
.filter(word -> word.length() > 5)
.sorted((o1, o2) -> o2.length() - o1.length())
.forEach(System.out::println);
}
利用函数式接口提升框架灵活度
前面章节中我们提到,JDK中有预置提供了很多的函数式接口,比如Supplier、Consumer、Predicate等,可又分别应用于不同场景的使用。当然咯,根据业务的实际需要,我们也可以去自定义需要的函数式接口,来方便我们自己的使用。
举个例子,有这么一个业务场景:
一个运维资源申请平台,需要根据资源规格不同计算各自资源的价格,最终汇总价格、并计算税额、含税总金额。
比如:
- 不同CPU核数、不同内存、不同磁盘大小的虚拟机,价格也是不一样的
- 1M、2M、4M等不同规格的网络带宽的费用也是不一样的
在写代码前,我们先分析下这个处理逻辑,并分析分类出其中的通用逻辑与定制可变逻辑,如下所示:
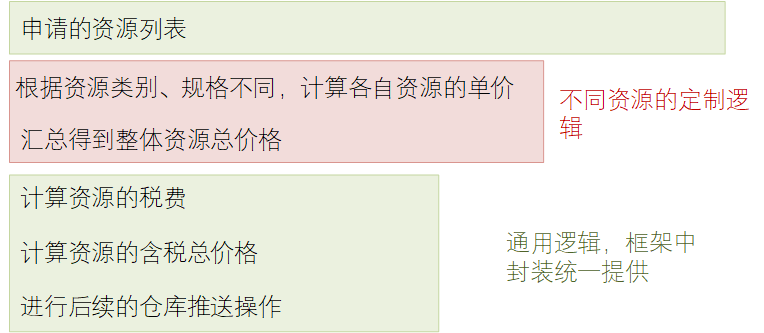
因为我们要做的是一个通用框架逻辑,且申请的资源类型很多,所以我们显然不可能直接在平台框架代码里面通过if else的方式来判断类型并在框架逻辑里面去写每个不同资源的计算逻辑。
那按照常规的思路,我们要将定制逻辑从公共逻辑中剥离,会定义一个接口类型,要求不同资源实体类都继承此接口类,实现接口类中的calculatePirce方法,这样在平台通用计算逻辑的时候,就可以通过泛型接口调用的方式来实现我们的目的:
public PriceInfo calculatePriceInfo(List<IResource> resources) {
// 计算总价
double price = resources.stream().collect(Collectors.summarizingDouble(IResource::calculatePrice)).getSum();
// 执行后续处理策略
PriceInfo priceInfo = new PriceInfo();
priceInfo.setPrice(price);
priceInfo.setTaxRate(0.15);
priceInfo.setTax(price * 0.15);
priceInfo.setTotalPay(priceInfo.getPrice() + priceInfo.getTax());
return priceInfo;
}
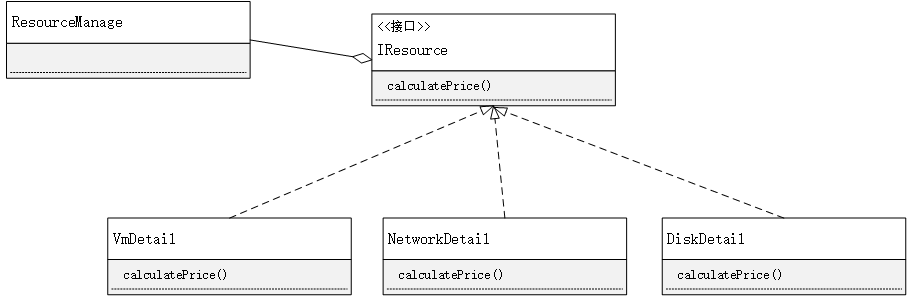
考虑到我们构建的平台代码的灵活性与可扩展性,能不能我们不要求所有资源都去实现指定接口类,也能将定制逻辑从平台逻辑中剥离呢?这里,就可以借助自定义函数式接口来实现啦。
再来回顾下函数式接口的要素是什么:
- 一个普通的JAVA interface类
- 此Interface类中有且仅有1个public类型的接口方法;
- (可选)添加个
@FunctionalInterface注解标识。
所以,满足上述3点的一个自定义函数式接口,我们可以很easy的就写出来:
@FunctionalInterface
public interface PriceComputer<T> {
double computePrice(List<T> objects);
}
然后我们在实现计算总价格的实现方法中,就可以将PriceComputer函数接口类作为一个参数传入,并直接调用函数式接口方法,获取到计算后的price信息,然后进行一些后续的处理逻辑:
public <T> PriceInfo calculatePriceInfo(List<T> resources, PriceComputer<T> priceComputer) {
// 调用函数式接口获取计算结果
double price = priceComputer.computePrice(resources);
// 执行后续处理策略
PriceInfo priceInfo = new PriceInfo();
priceInfo.setPrice(price);
priceInfo.setTaxRate(0.15);
priceInfo.setTax(price * 0.15);
priceInfo.setTotalPay(priceInfo.getPrice() + priceInfo.getTax());
return priceInfo;
}
具体调用的时候,对于不同资源的计算,具体各个资源单独计费的逻辑可以自行传入,无需耦合到上述的基础方法里面。例如需要计算一批不同规格的虚拟机的总价时,可以这样:
// 计算虚拟机总金额
functionCodeTest.calculatePriceInfo(vmDetailList, objects -> {
double result = 0d;
for (VmDetail vmDetail : objects) {
result += 100 * vmDetail.getCpuCores() + 10 * vmDetail.getDiskSizeG() + 50 * vmDetail.getMemSizeG();
}
return result;
});
同样地,如果想要计算一批带宽资源的费用信息,我们可以这么来实现:
// 计算磁盘总金额
functionCodeTest.calculatePriceInfo(networkDetailList, objects -> {
double result = 0d;
for (NetworkDetail networkDetail : objects) {
result += 20 * networkDetail.getBandWidthM();
}
return result;
});
单看调用的逻辑,也许你会有个疑问,这也没看出代码会有啥特别的优化改进啊,跟我直接封装两个私有方法似乎也没啥差别?甚至还更复杂了?但是看calculatePriceInfo方法会发现其作为基础框架的能力更加通用了,将可变部分的逻辑抽象出去由业务调用方自行传入,而无需耦合到框架里面了(很像回调接口的感觉)。
函数式接口与Lambda的完美搭配
Lambda语法是JAVA8开始引入的一种全新的语法糖,可以进一步的简化编码的逻辑。在函数式接口的具体使用场景,如果结合Lambda表达式,可以使得编码更加的简洁、不拖沓。
我们都知道,在JAVA中的接口类是不能直接使用的,必须要有对应的实现类,然后使用具体的实现类。而有些时候如果没有必要创建一个独立的类时,则需要创建内部类或者匿名实现类来使用:
public void testNonLambdaUsage() {
new Thread() {
@Override
public void run() {
System.out.println("new thread executing...");
}
}.start();
}
这里使用了匿名类的方式,先实现一个Runnable函数式接口的具体实现类,然后执行此实现类的 start()方法。而使用Lambda语法来实现,整个代码就会显得很清晰了:
public void testLambdaUsage() {
new Thread(() -> System.out.println("new thread executing...")).start();
}
所以说,Lambda不是使用函数式编程的必需品,但是只有结合Lambda使用,才能将函数式接口优势发挥出来、才能将函数式编程的思想诠释出来。
编程范式的演进思考
前面的章节中呢,我们一起探讨了下函数式接口的一些内容,而函数式接口也是函数式编程中的一部分。这里说的函数式编程,其实是常见编程范式中的一种,也就是一种编程的思维方式或者实现方式。主流编程范式有命令式编程与声明式编程,而函数式编程也即是声明式编程思想的具体实践。
那么,该如何理解命令式编程与声明式编程呢?先看个例子。
假如周末的中午,我突然想吃鸡翅了,然后我自己动手,一番忙活之后,终于吃上鸡翅了(不容易啊)!
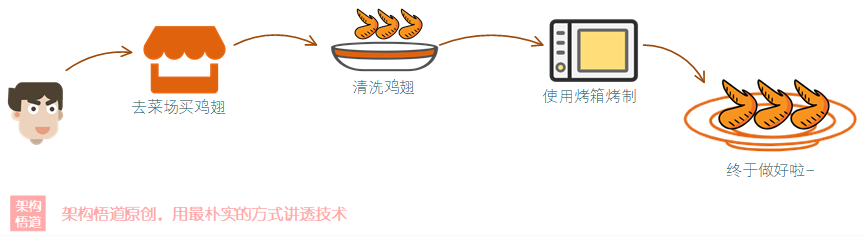
为了实现“吃鸡翅”这个目的,然后是具体的一步一步的去做对应的事情,最终实现了目的,吃上了鸡翅。——这就是 命令式编程。
中午吃完烤鸡翅,我晚上还想再吃烤鸡腿,但我不想像中午那样去忙活了,于是我:
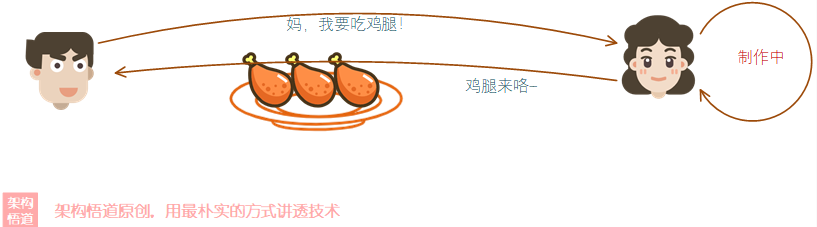
照样如愿的吃上鸡腿了(比中午容易多了)。这里的我,只需要声明要吃鸡腿就行了,至于这个鸡腿是怎么做出来的,完全不用关心。——这就是 声明式编程。
从上面的例子中,可以看出两种不同编程风格的区别:
- 命令式编程的主要思想是关注计算机执行的步骤,即一步一步告诉计算机先做什么再做什么。各种主流编程语言如C、C++、JAVA等都可以遵循这种方式去写代码。
- 声明式编程的主要思想是告诉计算机应该做什么,但不指定具体要怎么做。典型的声明式编程语言,比如:SQL语言、正则表达式等。
回到代码中,现在有个需求:
从给定的一个数字列表collection里面,找到所有大于5的元素,用命令式编程的风格来实现,代码如下:
List<Integer> results = new ArrayList<>();
for (int num : collection) {
if (num > 5) {
results.add(num);
}
}
而使用声明式编程的时候,代码如下:
List<Integer> results =
collection.stream().filter(num -> num > 5).collect(Collectors.toList());
声明式编程的优势,在于其更关注于“要什么”、而会忽略掉具体怎么做。这样整个代码阅读起来会更加的接近于具体实际的诉求,比如我只需要告诉 filter要按照 num > 5这个条件来过滤,至于这个filter具体是怎么去过滤的,无需关心。
总结
好啦,关于函数式接口相关的内容,就介绍到这里啦。那么看到这里,相信您应该有所收获吧?那么你对函数式编程如何看呢?评论区一起讨论下吧、我会认真对待并探讨每一个评论~~
此外:
- 关于本文中涉及的演示代码的完整示例,我已经整理并提交到github中,如果您有需要,可以自取:https://github.com/veezean/JavaBasicSkills
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点赞 + 关注让我感受到您的支持。也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。











